Analysis of DeepSeek Versions and Their Strengths and Weaknesses
DeepSeek is a language model series that has recently garnered significant attention in the field of artificial intelligence. Throughout its various version releases, it has progressively enhanced its ability to handle multiple tasks. This article will provide an in-depth introduction to DeepSeek’s versions, covering their release dates, features, advantages, and disadvantages, serving as a reference guide for AI enthusiasts and developers.
1. DeepSeek-V1: Strong Start with Robust Coding Capabilities
DeepSeek-V1 marks the initial version of DeepSeek; here, we will focus primarily on analyzing its pros and cons.
Release Date:
January 2024
Features:
As the first version in the DeepSeek series, DeepSeek-V1 was pre-trained on 2TB of labeled data. It excels in natural language processing and coding tasks, supporting multiple programming languages with robust coding capabilities, making it suitable for developers and technical researchers.
Advantages:
- Strong Coding Capabilities: Supports multiple programming languages, capable of understanding and generating code, ideal for automated code generation and debugging by developers.
- High Context Window: Supports up to 128K token context windows, enabling handling of complex text understanding and generation tasks.
Disadvantages:
- Limited Multimodal Capabilities: This version primarily focuses on text processing with limited support for image, voice, and other multimodal tasks.
- Weak Reasoning Capabilities: While excelling in natural language processing and coding, it underperforms compared to subsequent versions in complex logical reasoning and deep inference tasks.
2. DeepSeek-V2 Series: Performance Enhancements and Open Source Ecosystem
As an early version of DeepSeek, the performance improvement from DeepSeek-V1 to DeepSeek-V2 is comparable to the gap between ChatGPT’s first version and ChatGPT 3.5.
Release Date:
First half of 2024
Features:
The DeepSeek-V2 series is equipped with 2360 billion parameters, making it an efficient and powerful version. It stands out for its high performance and low training costs, supports full open source, and free commercial use, greatly promoting the popularization of AI applications.
Advantages:
- Efficient Performance and Low Cost: Training cost is just 1% of GPT-4-Turbo, significantly reducing development thresholds, suitable for academic research and commercial applications.
- Open Source and Free Commercial Use: Compared to the previous version, V2 supports full open source, allowing users to freely use it commercially. This makes DeepSeek’s ecosystem more open and diverse.
Disadvantages:
- Slow Inference Speed: Despite its massive number of parameters, the inference speed of DeepSeek-V2 is slower compared to subsequent versions, impacting performance in real-time tasks.
- Limited Multimodal Capabilities: Similar to V1, the V2 version performs inadequately when handling non-text tasks such as images and audio.
3. DeepSeek-V2.5 Series: Breakthroughs in Mathematics and Web Search
Release Date:
September 2024
Here is the official update log for the V2.5 version:
DeepSeek has always been dedicated to improving its models. In June, we made a major upgrade to DeepSeek-V2-Chat by replacing its original Chat Base model with Coder V2’s Base model, significantly enhancing its code generation and reasoning capabilities, and releasing the DeepSeek-V2-Chat-0628 version. Following that, DeepSeek-Coder-V2 was launched on top of the existing Base model through alignment optimization, greatly improving general capabilities to introduce the DeepSeek-Coder-V2 0724 version. Finally, we successfully merged Chat and Coder into a brand new DeepSeek-V2.5 version.
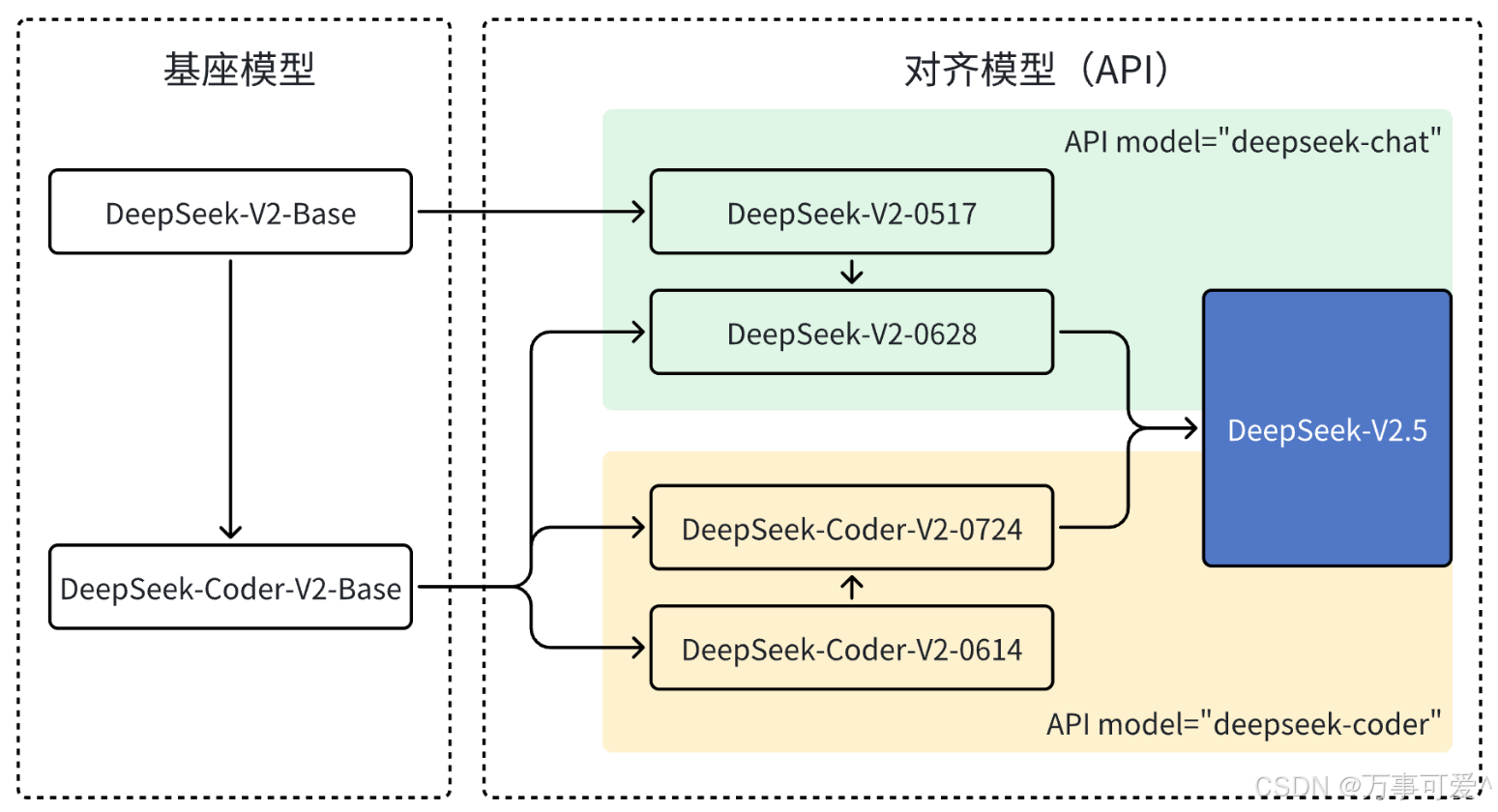
It can be seen that the official update has integrated the Chat and Coder models, enabling DeepSeek-V2.5 to assist developers in handling more challenging tasks.
- Chat Model: Specifically designed and optimized for dialogue systems (chatbots), used for generating natural language conversations, capable of understanding context and producing coherent and meaningful responses, commonly applied in chatbots, intelligent assistants, etc.
- Coder Model: An AI model based on deep learning technology, trained on extensive code data, able to understand, generate, and process code.
From the official released data, compared to V2 model, DeepSeek-V2.5 has shown significant improvements in general capabilities (creation, Q&A, etc.).
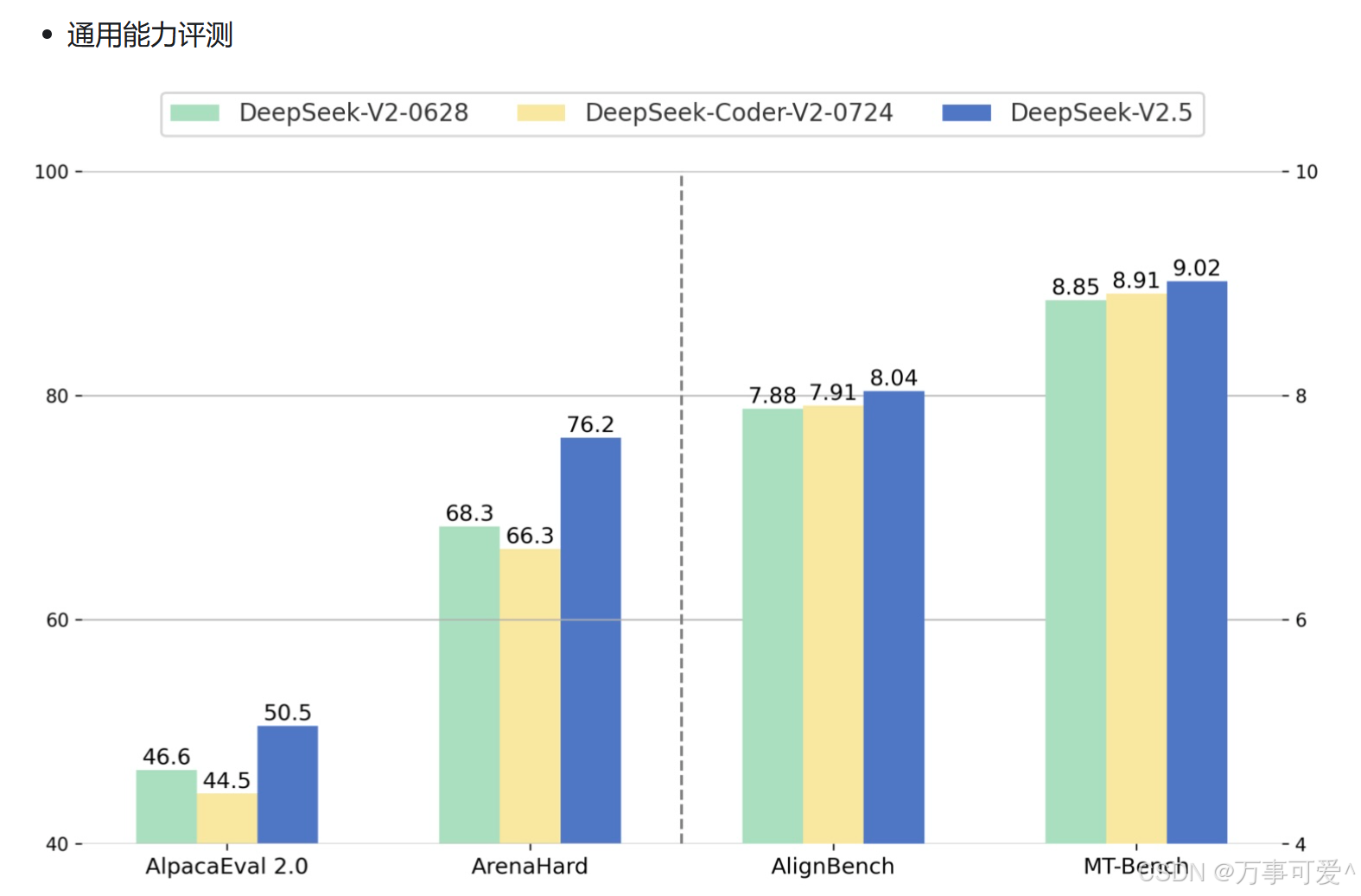
Below is a comparison between DeepSeek – V2 and DeepSeek – V2.5 with ChatGPT4o – latest and ChatGPT4o mini in terms of general capabilities.
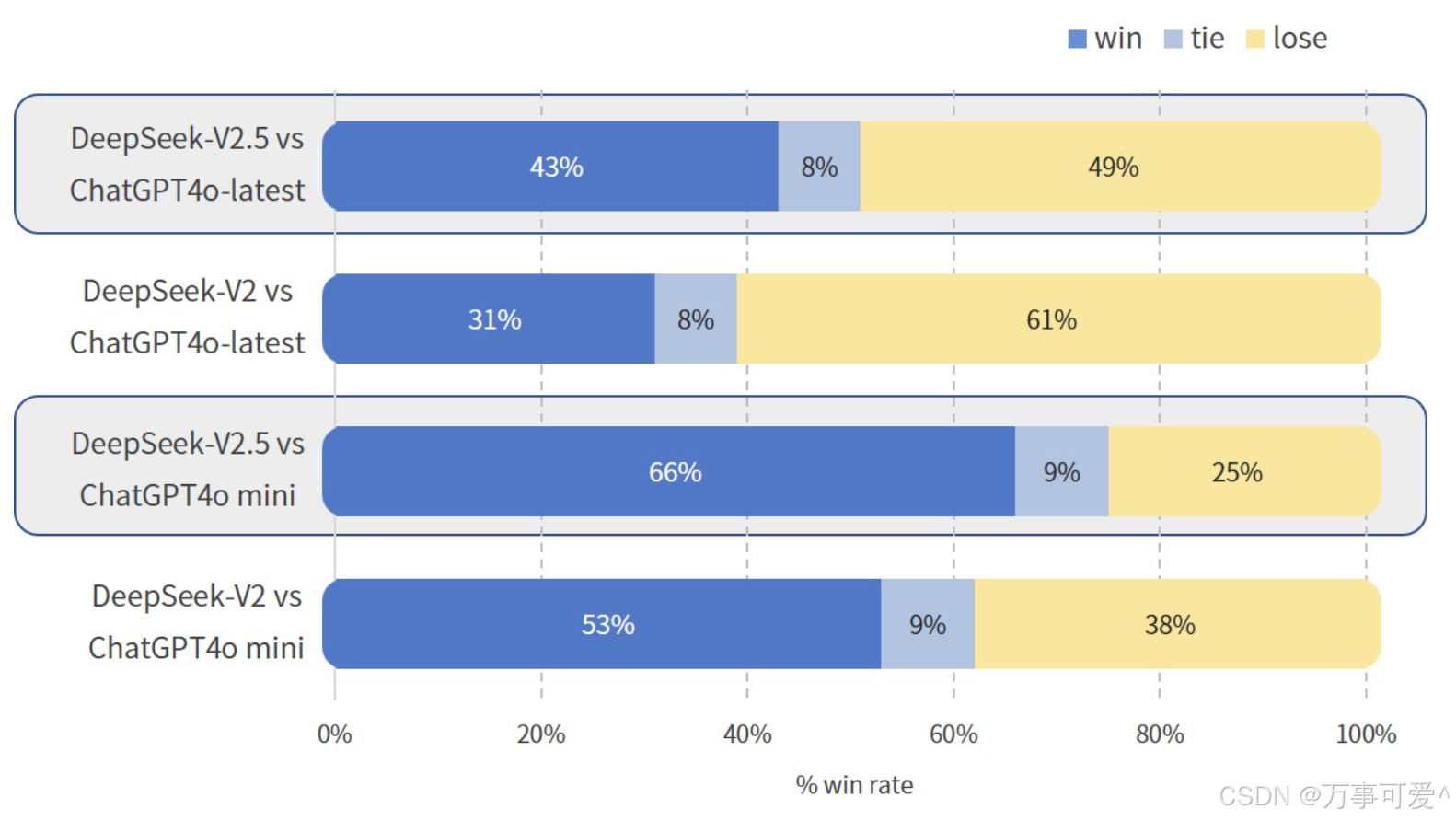
From this graph, we can see the win rate, tie rate, and loss rate of DeepSeek – V2.5 and DeepSeek – V2 against ChatGPT4o – latest and ChatGPT4o mini:
- DeepSeek – V2.5 vs ChatGPT4o – latest: DeepSeek – V2.5 has a 43% win rate, 8% tie rate, and 49% loss rate.
- DeepSeek – V2 vs ChatGPT4o – latest: DeepSeek – V2 has a 31% win rate, 8% tie rate, and 61% loss rate.
- DeepSeek – V2.5 vs ChatGPT4o mini: DeepSeek – V2.5 has a 66% win rate, 9% tie rate, and 25% loss rate.
- DeepSeek – V2 vs ChatGPT4o mini: DeepSeek – V2 has a 53% win rate, 9% tie rate, and 38% loss rate.
In comparison with the ChatGPT4o series models, DeepSeek – V2.5 performs better overall than DeepSeek – V2; when compared to ChatGPT4o mini, DeepSeek – V2.5 and DeepSeek – V2 have relatively higher win rates, but their win rates are relatively lower when compared to ChatGPT4o – latest.
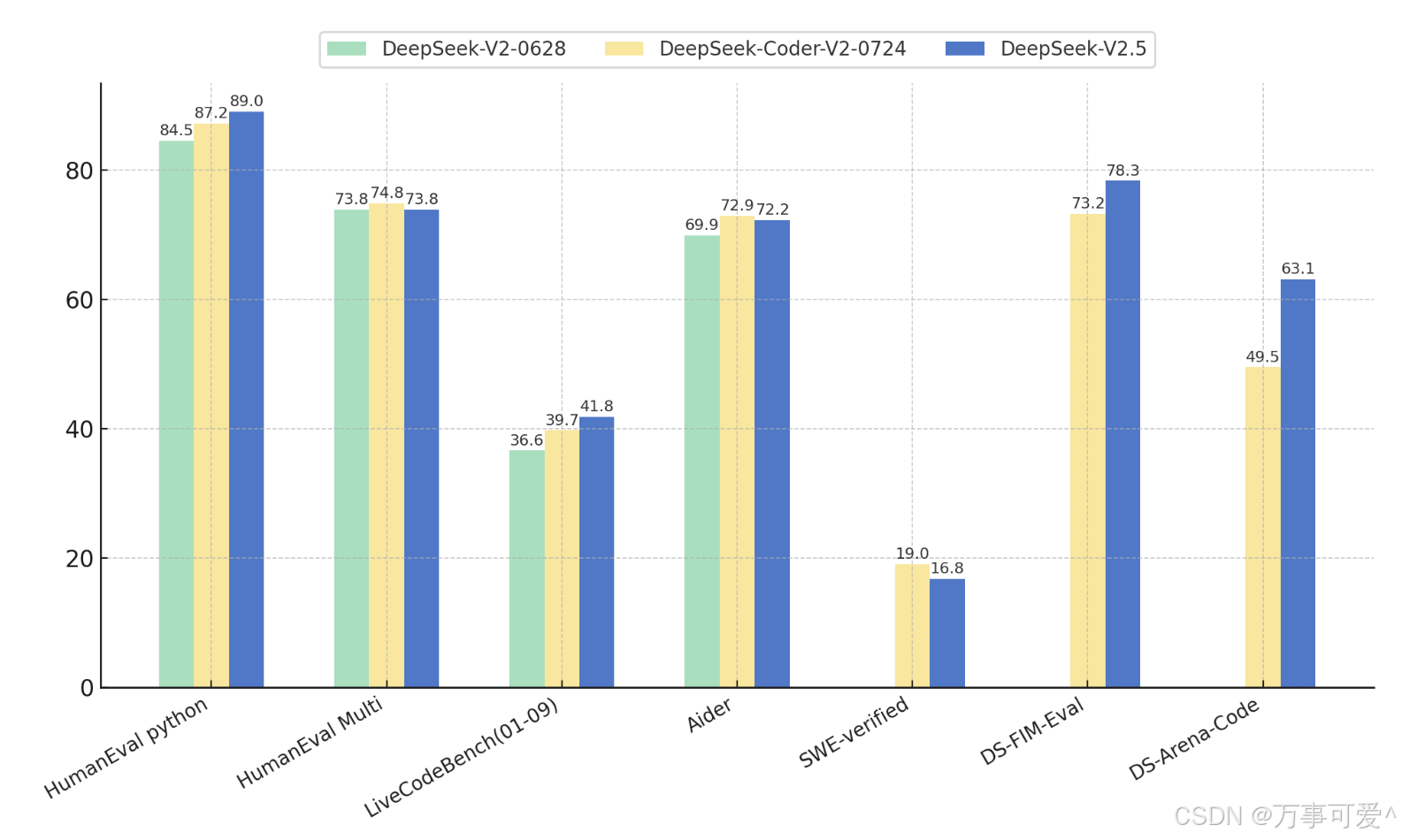
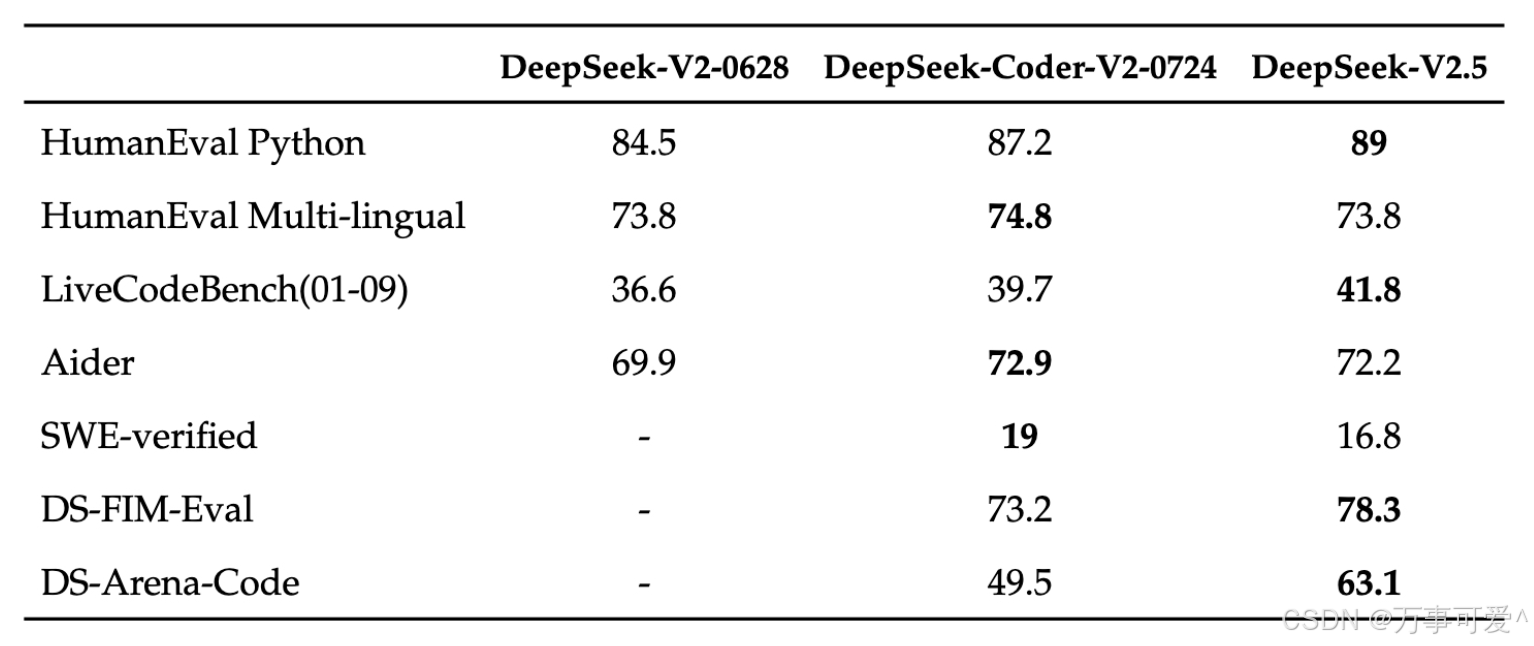
Regarding code capabilities, DeepSeek-V2.5 retains the powerful coding abilities of DeepSeek-Coder-V2-0724. In HumanEval
Python and LiveCodeBench (January 2024 – September 2024) tests, DeepSeek-V2.5 demonstrated significant improvements. In HumanEval Multilingual and Aider tests, DeepSeek-Coder-V2-0724 slightly outperformed. In SWE-verified
tests, both versions performed relatively lower, indicating the need for further optimization in this area. Additionally, in FIM completion tasks, the score on the internal evaluation set DS-FIM-Eval improved by
5.1%, offering a better plugin completion experience.Furthermore, DeepSeek-V2.5 optimized common code scenarios to enhance practical performance. In the internal subjective evaluation DS-Arena-Code,
DeepSeek-V2.5 achieved a significant increase in win rates against competitors (with GPT-4o as referee).
Features:
DeepSeek-V2.5 made key improvements over the previous version, particularly excelling in mathematical reasoning and writing. Additionally, this version introduced internet search functionality, enabling real-time analysis of massive web information, enhancing the model’s timeliness and data richness.
Advantages:
- Enhanced Math and Writing Capabilities: DeepSeek-V2.5 excels in complex mathematical problems and creative writing, assisting developers in handling more challenging tasks.
- Internet Search Functionality: By accessing the internet, the model can retrieve the latest web information, analyze, and understand current online resources, enhancing its real-time performance and breadth of information.
Disadvantages:
- API Limitations: Although it has the ability to search online, the API interface does not support this function, affecting some users’ practical application scenarios.
- Limited Multimodal Capabilities: Despite improvements in various aspects, DeepSeek V2.5 still has limitations in multimodal tasks and cannot compete with dedicated multimodal models.
DeepSeek-V2.5 is now open-sourced on HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V2.5
4. DeepSeek-R1-Lite Series: Inference model preview released, unlocking the o1 inference process
Release Date:
November 20, 2024
It cannot be denied that DeepSeek’s iteration speed is very fast. In November of the same year, the historically significant R1-Lite model was released. As a precursor to the R1 model, although it did not receive as much attention as R1, as a domestic inference model targeting OpenAI o1, its performance is still commendable. The DeepSeek-R1-Lite preview version model achieved outstanding results in authoritative evaluations such as the American Mathematics Competitions (AMC) at the highest difficulty level (AIME) and global top-tier programming competitions (Codeforces), significantly outperforming renowned models like GPT-4.
Below is a table of DeepSeek-R1-Lite’s scores in various related evaluations:
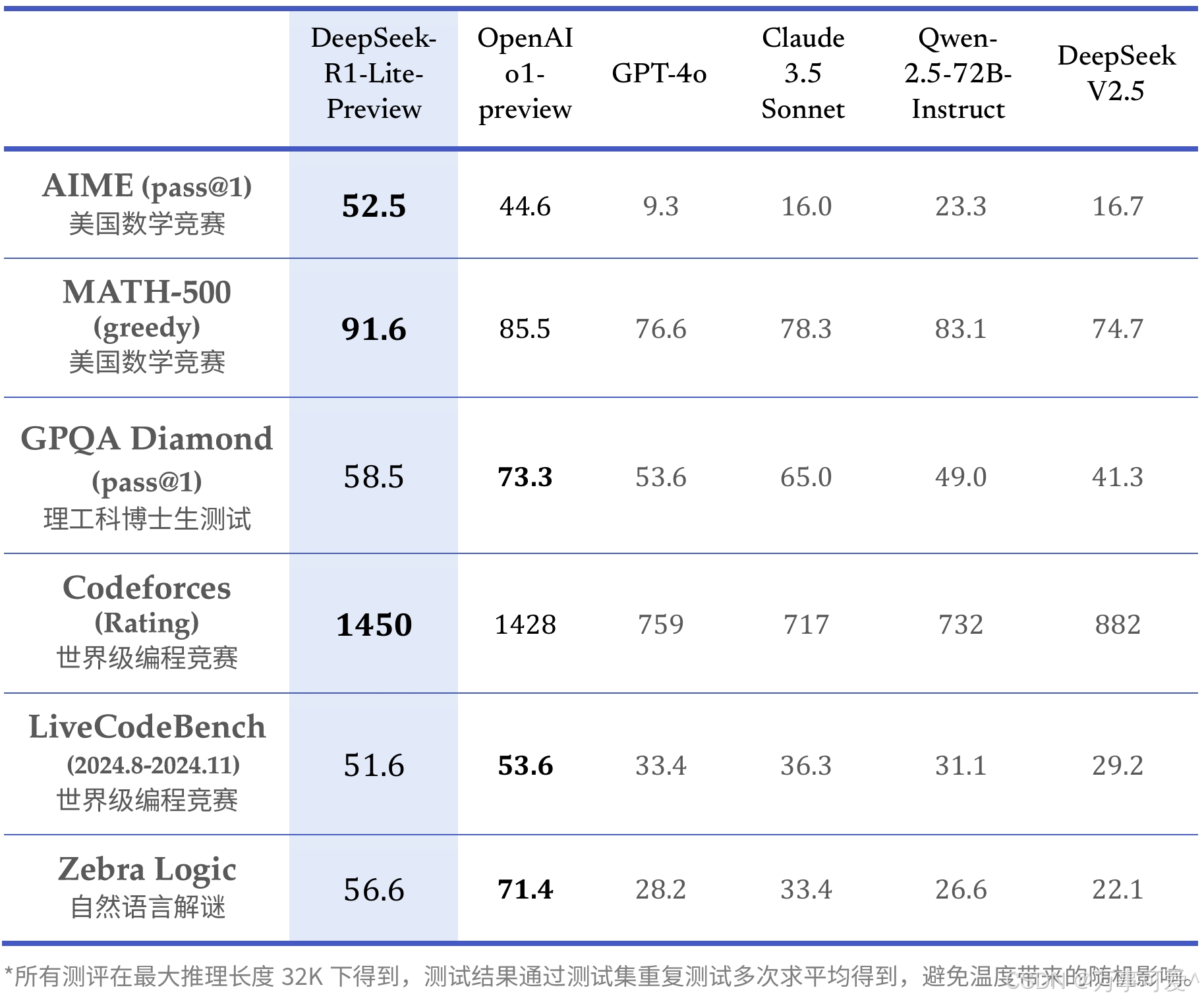
DeepSeek – R1 – Lite – Preview demonstrated outstanding performance in math competitions (AIME, MATH – 500) and world-class programming competitions (Codeforces). It also showed decent results in tests for Ph.D. students in STEM fields and another world-class programming competition, as well as natural language puzzle tasks. However, OpenAI o1 – preview scored higher in tasks such as the Ph.D.-level STEM tests and natural language puzzle tasks, which is why DeepSeek – R1 – Lite has not garnered much attention.
According to official website news, the reasoning process of DeepSeek-R1-Lite is lengthy and involves a substantial amount of reflection and verification. The following figure demonstrates that the model’s score in mathematics competitions is closely related to the permitted thinking length during testing.

From the above figure, it can be observed that:
- The accuracy of DeepSeek – R1 – Lite – Preview improves significantly with an increase in average token quantity. The enhancement is more pronounced when majority voting is applied, ultimately surpassing the performance of OpenAI o1 – preview.
- Under one-pass (Pass@1) conditions, the accuracy of DeepSeek – R1 – Lite – Preview exceeds that of OpenAI o1 – preview’s 44.2% once the average token quantity reaches a certain level.
Characteristics
Trained using reinforcement learning, the reasoning process incorporates extensive reflection and verification, with a chain of thought reaching tens of thousands of characters. It excels in tasks requiring long logical chains such as mathematics and programming, achieving comparable inference results to o1 and demonstrating the complete thinking process not publicly disclosed by o1. Currently available for free on the DeepSeek official website.
Advantages
- Strong reasoning ability: Performs exceptionally well in high-difficulty mathematics and code tasks, outperforming existing top models in US Mathematics Competitions (AMC) and global programming competitions (Codeforces). It even surpasses OpenAI’s o1 in certain tasks. For example, it successfully decrypted a password dependent on complex logic, while o1 – preview failed to provide the correct solution.
- Detailed thinking process: Provides not only answers but also detailed reasoning and reverse-thinking verification processes, showcasing rigorous logical inference.
- High cost-effectiveness: DeepSeek’s products primarily follow an open-source approach. Its training costs are significantly lower than those of industry-leading models, offering a notable advantage in terms of value for money.
Disadvantages
- Unstable code generation performance: Performs below expectations when generating relatively simple code.
- Inadequate knowledge referencing capability: Fails to achieve satisfactory results in complex tests requiring modern knowledge references.
- Language interaction issues: May experience confusion during use between Chinese and English thinking and output processes.
5. DeepSeek-V3 Series: Large-scale models and inference speed improvements
Release Date:
December 26, 2024
As the first self-developed hybrid expert (MoE) model by DeepSeek Inc., it features 6710 billion parameters and 370 billion activations, having completed pre-training on 14.8 trillion tokens.
DeepSeek-V3 outperforms other open-source models like Qwen2.5-72B and Llama-3.1-405B in multiple evaluations and matches the performance of top-tier closed-source models such as GPT-4o and Claude-3.5-Sonnet.

DeepSeek – V3 excels in MMLU – Pro, MATH 500, and Codeforces task tests with high accuracy; it also shows good performance in GPQA Diamond and SWE – bench Verified tasks. However, GPT – 4o – 0513 has a higher accuracy rate in the AIME 2024 task.

From the above table, it can be seen that this comparison involves models such as DeepSeek – V3, Qwen2.5 – 72B – Inst, Llama3.1 – 405B – Inst, Claude – 3.5 – Sonnet – 1022, and GPT – 4o – 0513. The analysis covers model architecture, parameters, and performance across various test sets:
Model Architecture and Parameters
- DeepSeek – V3: Uses MoE architecture with 37B activation parameters and a total of 671B parameters.
- Qwen2.5 – 72B – Inst: Dense architecture with 72B activation parameters and a total of 72B parameters.
- Llama3.1 – 405B – Inst: Dense architecture with 405B activation parameters and a total of 405B parameters.
- Information on the other two models is not currently available.
English Test Set Performance
- MMLU Related: DeepSeek – V3 achieved scores of 88.5, 89.1, and 75.9 in MMLU – EM, MMLU – Redux EM, and MMLUPro – EM tests respectively, performing similarly to other models in some tests.
- DROP: DeepSeek – V3 scored 91.6, outperforming other models.
- IF – Eval: DeepSeek – V3 achieved a score of 86.1, comparable to other models’ performance.
- GPQA – Diamond: With a score of 59.1, DeepSeek – V3 trails Claude – 3.5 – Sonnet – 1022’s 65.
- SimpleQA and Others: In tests such as SimpleQA, FRAMES, LongBench v2, DeepSeek – V3 showed varying performance, scoring 24.9 in SimpleQA and 73.3 in FRAMES.
Code Test Set Performance
- HumanEval – Mul: DeepSeek – V3 scored 82.6, demonstrating strong performance.
- LiveCodeBench: In LiveCodeBench (Pass@1 – COT) and LiveCodeBench (Pass@1) tests, DeepSeek – V3 achieved scores of 40.5 and 37.6 respectively.
- Codeforces and Others: DeepSeek – V3 scored 51.6 in Codeforces Percentile test and 42 in SWE – bench Verified (Resolved).
<h5)Math Test Set Performance
- AIME 2024: With a score of 39.2, DeepSeek – V3 outperformed Qwen2.5 – 72B – Inst, Llama3.1 – 405B – Inst, and Claude – 3.5 – Sonnet – 1022.
- MATH – 500: DeepSeek – V3 achieved a score of 90.2, showing significant advantages.
Performance on Chinese Test Sets
- CLUEWSC: DeepSeek – V3 achieves a score of 90.9, comparable to other models.
- C-Eval etc.: In C-Eval and C-SimpleQA tests, DeepSeek – V3 scores 86.5 and 64.1 respectively.
Overall, DeepSeek – V3 demonstrates strong performance across multiple test sets, with significant advantages in DROP and MATH-500 benchmarks. Different models show varying strengths and weaknesses across language and domain-specific tests.
Features:
DeepSeek-V3 represents a milestone version in its series, equipped with 6710 billion parameters, focusing on knowledge-based tasks and mathematical reasoning, with substantial performance improvements. V3 introduces native FP8 weights, supports local deployment, and significantly enhances inference speed, increasing generation throughput from 20 TPS to 60 TPS, meeting the demands of large-scale applications.
Strengths:
- Strong reasoning capabilities: With its 6710 billion parameters, DeepSeek-V3 excels in knowledge-based reasoning and mathematical tasks.
- High generation speed: Achieving a generation speed of 60 characters per second (TPS), V3 meets the requirements for high-response-speed application scenarios.
- Support for local deployment: Through open-sourcing FP8 weights, users can deploy locally, reducing reliance on cloud services and enhancing data privacy.
Weaknesses:
- High training resource requirements: While inference capabilities have been significantly enhanced, V3 requires substantial GPU resources for training, leading to high deployment and training costs.
- Weak multi-modal capabilities: Similar to previous versions, V3 has not undergone specific optimizations for multi-modal tasks (such as image understanding), leaving room for improvement in this area.
Please find the paper link of V3 model below for reference.
Paper Link: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
6. DeepSeek-R1 Series: Enhanced with reinforcement learning and research applications, performance targeting OpenAI o1 official version
Release Date:
January 20, 2025
As a highly anticipated model since its release, DeepSeek-R1 has undergone numerous challenges to reach where it is today. Since its launch, DeepSeek-R1 has adhered to the principles of openness, following the MIT License. This allows users to leverage distillation technology to train other models using R1.
This will have the following two impacts:
License Level
The MIT License is a permissive license for open-source software. This means DeepSeek – R1 approaches developers and users in an extremely open manner. Within the bounds of the MIT License, users have significant freedom:
- Usage Freedom: Can be used freely in various scenarios such as personal projects or commercial projects without worrying about legal issues related to usage.
- Modification Freedom: Able to modify and customize the code and model architecture of DeepSeek – R1 to meet specific business needs or research objectives.
- Distribution Freedom: Can distribute modified or unmodified versions of DeepSeek – R1, whether for free or bundled with commercial products, which is permitted.
Model Training and Technical Application Level
Allowing users to train other models using distillation technology based on R1 has significant technical value and application potential:
- Model Lightweighting: Distillation technology can transfer the knowledge of the large DeepSeek – R1 model to smaller models. Developers can train lighter, more efficient models, such as deploying models on resource-constrained devices (e.g., mobile devices, embedded devices) to achieve real-time inference and application without relying on powerful computing resources to run the original large DeepSeek – R1 model.
- Customization: Users can tailor their specific task requirements, such as specific domain text classification or specific type image recognition, based on DeepSeek – R1 through distillation training. This results in a better balance between performance and resource consumption, enhancing the model’s performance in specific scenarios.
- Technology Innovation Promotion: This approach provides researchers and developers with a powerful tool and starting point, encouraging more exploration and innovation based on DeepSeek – R1, accelerating the application of artificial intelligence technology across industries, and driving overall technological advancement.
Furthermore, DeepSeek-R1 has launched its API, allowing users to access the reasoning chain output by setting model=‘deepseek-reasoner’. This undoubtedly greatly facilitates individual users interested in large language models.
According to official website information, DeepSeek-R1 massively utilized reinforcement learning techniques in post-training, significantly enhancing its inference capabilities even with minimal labeled data. Its performance in mathematics, code understanding, and natural language reasoning tasks is comparable to OpenAI o1 official version.
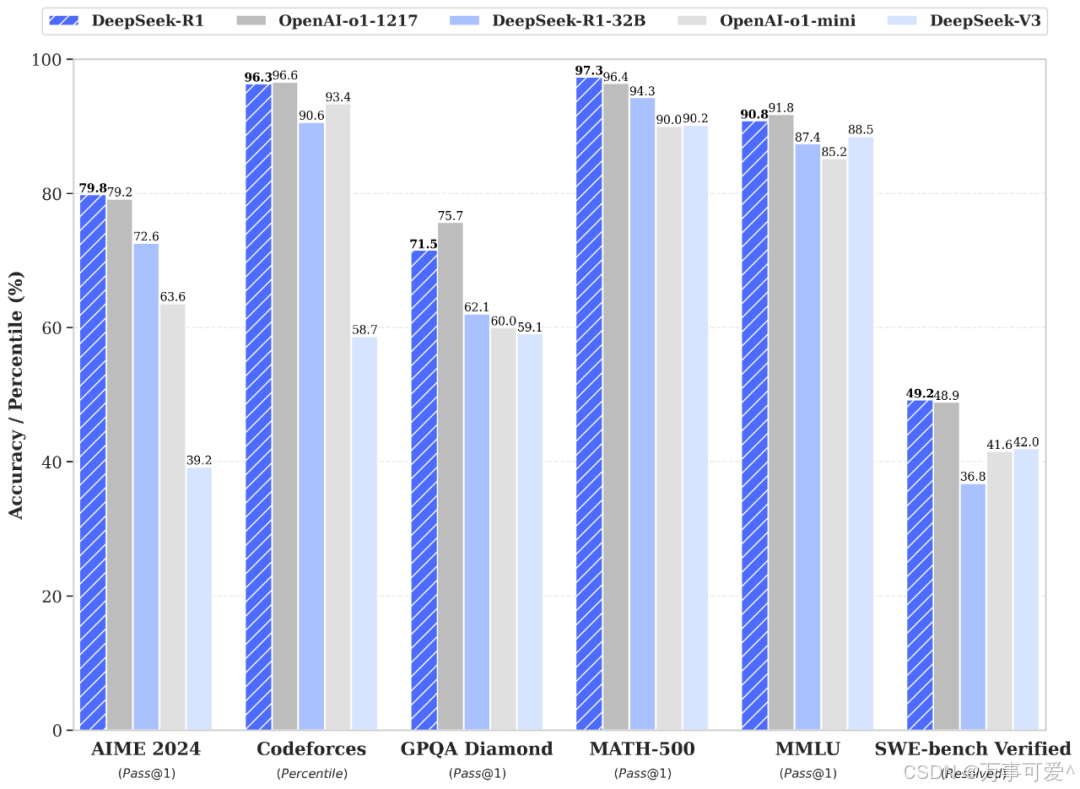
From the above figure, it can be seen that DeepSeek-R1 or DeepSeek-R1-32B performs outstandingly in Codeforces, MATH – 500, and SWE – bench Verified tests; OpenAI-o1-1217 performs better in AIME 2024, GPQA Diamond, and MMLU tests.
However, in the comparison of distilling small models, R1 model outperforms OpenAI o1-mini.
Officially, two 660B models, DeepSeek-R1-Zero and DeepSeek-R1, have been open-sourced. Through the output of DeepSeek-R1, six small models have been distilled and released to the community. Among them, the 32B and 70B models achieve comparable performance to OpenAI o1-mini across multiple capabilities.
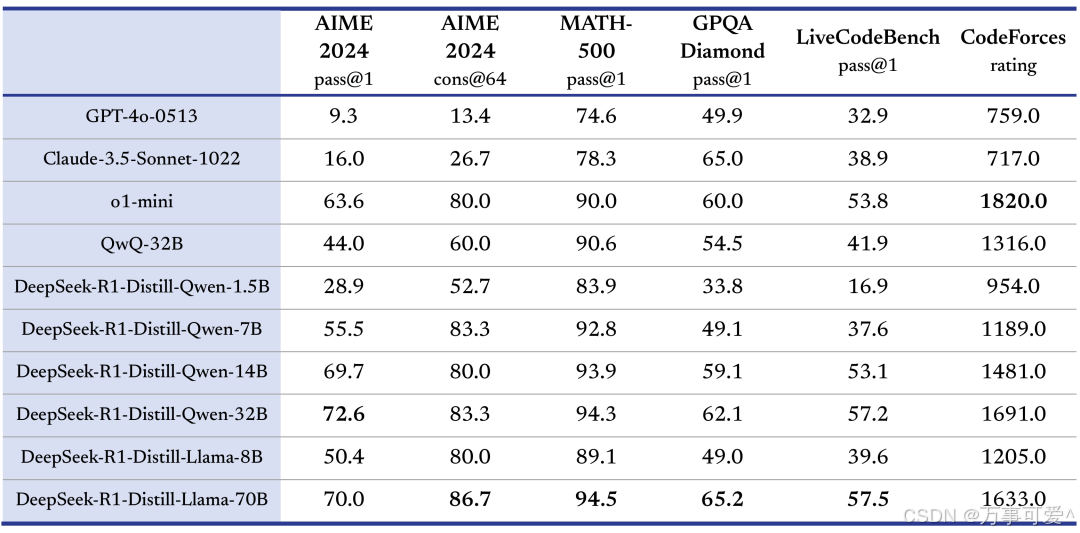
The table above compares the performance of different models across multiple test sets, including AIME 2024 and MATH – 500, with models such as GPT-4o-0513, Claude-3.5-Sonnet-1022, and various DeepSeek-R1 distilled models. Specific analysis is as follows:
Model and Performance
- GPT-4o-0513 performs relatively evenly across various test sets.
- Claude-3.5-Sonnet-1022 demonstrates strong performance particularly in natural language understanding tasks.
- DeepSeek-R1 shows superior capabilities in code interpretation and mathematical reasoning, outperforming other models in these specialized areas.
Summary
From the table, it is evident that o1 – mini shows a significant advantage in CodeForces competition ratings; DeepSeek – R1’s distilled large-parameter models (such as DeepSeek – R1 – Distill – Qwen – 32B and DeepSeek – R1 – Distill – Llama – 70B) demonstrate better performance on math and programming-related test sets, reflecting the enhancing effect of DeepSeek – R1 distillation technology on model capabilities. Different models exhibit varying strengths across different test sets.
Features:
DeepSeek-R1 represents the latest version in the series, optimized for inferencing capability through reinforcement learning (RL) techniques. The R1 version’s inferencing ability is comparable to OpenAI’s O1, and it adheres to the MIT License, supporting model distillation, which further promotes the healthy development of open-source ecosystems.
Advantages:
- Enhanced Inference Capabilities via Reinforcement Learning: By leveraging reinforcement learning technology, R1 demonstrates stronger performance in inferencing tasks compared to other versions.
- Open Source Support and Academic Applications: The complete open-source nature of R1 facilitates further development by researchers and technical developers, thereby accelerating advancements in AI technologies.
Disadvantages:
- Limited Multimodal Capabilities: Despite significant improvements in inferencing abilities, the support for multimodal tasks remains inadequately optimized.
- Application Scope Restrictions: R1 primarily targets academic research, technical development, and educational domains, with relatively limited applicability in commercial applications and real-world operations.
As usual, the link to the R1 paper is provided below for reference.
Paper Link: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
Conclusion
The continuous iteration and improvement of the DeepSeek series reflect its ongoing progress in natural language processing, inferencing capabilities, and application ecosystems. Each version offers unique strengths and applicable scenarios, enabling users to choose the one that best meets their needs. As technology evolves, future advancements in DeepSeek are anticipated, particularly in areas like multimodal support and inferencing capabilities, making it a series worth following.
Leave a Reply
You must be logged in to post a comment.